Мифы о нейросетях: верить или нет? Разбираемся с экспертом!
Дима Мокеев, руководитель группы качества пре-обучения нейросетей, подтверждает слухи про ИИ. И опровергает их — причём одновременно.
3 июня 2025нейросеть
экология
ИИ-подхалим
краш-тесты
Дима Мокеев, руководитель группы качества пре-обучения нейросетей, подтверждает слухи про ИИ. И опровергает их — причём одновременно.
3 июня 2025В интернете много чего пишут. Но всему ли можно верить? Конечно же нет! Мы взяли последние новости из мира AI и попросили руководителя группы качества претрейна Диму Мокеева, и по совместительству выпускника ШАД, рассказать, действительно ли всё так страшно, как транслируют журналисты.
Дима Мокеев — выпускник ШАД 2023 года, закончил бакалавриат по профилю «Компьютерные технологии» в МФТИ и сейчас там же проходит обучение по магистерской программе «Анализ данных». Первая его работа была связана с программированием на С++, а теперь Дима руководит целой командой в Яндексе, которая занимается базовым обучением нейросетей.
Пугают, что по мере развития искусственного интеллекта, на обеспечение его работы требуется всё больше энергии. А эта энергия в основном вырабатывается за счет сжигания угля и газа, что является основным фактором изменения климата.
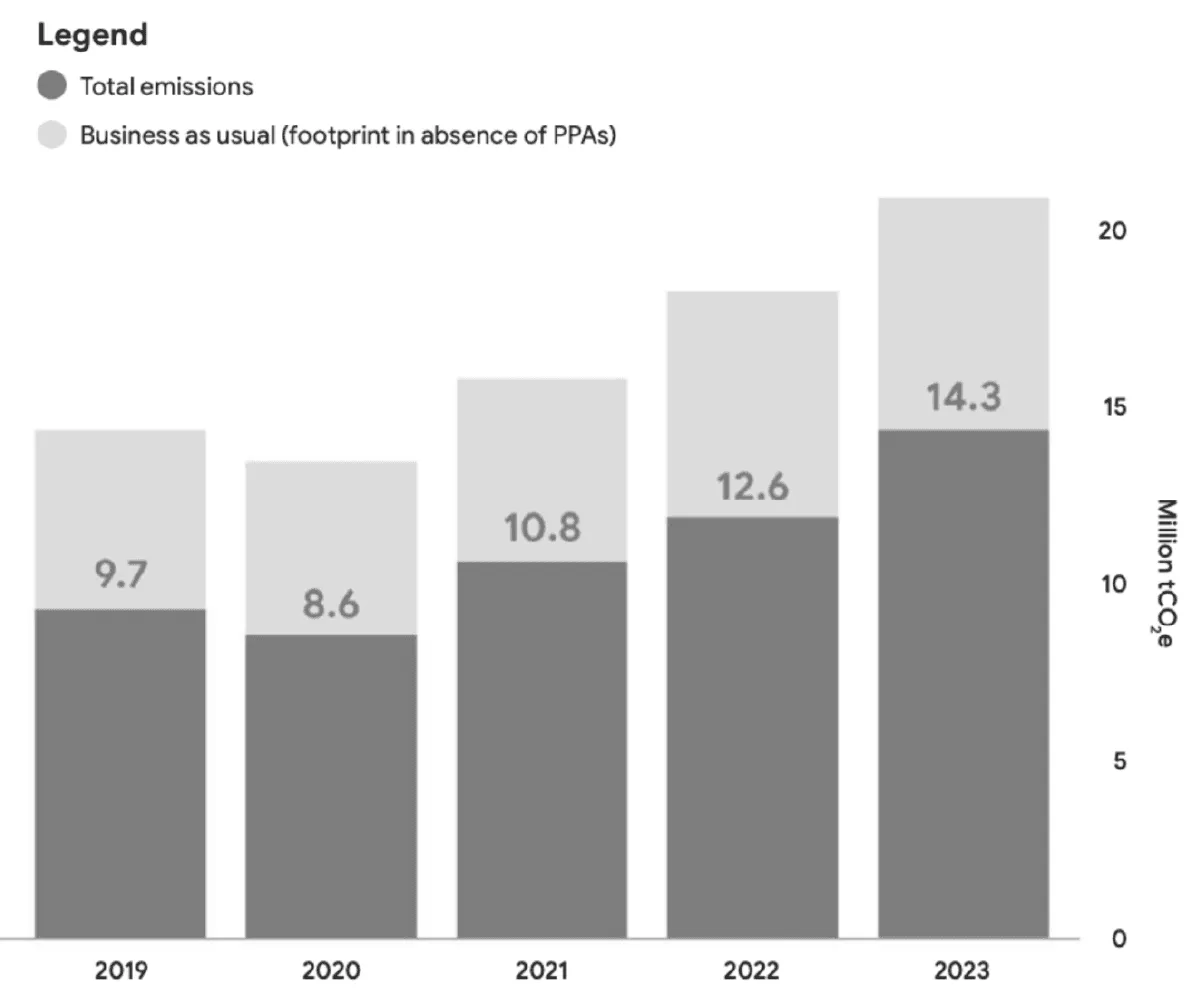
Дима: Есть два фактора, по которым можно сразу сказать, оправданы ли такие «обвинения». Во-первых, начиная с GPT 3.5, все модели OpenAI, это черные ящики, и никто не знает, сколько они на самом деле весят. По крайней мере, официально такие данные компания не показывает. А во-вторых, реальная стоимость запросов в GPT зависит от большого количества факторов. Например, от видеокарт, которые компания использует для вывода — непосредственно генерации текста ответа. В статье приводится отчет об экологической устойчивости от Google. Если посмотреть на него внимательно, то видно, что выбросы эквивалента углекислого газа (tCO2e) показаны на основе работы всех сервисов компании.
Самый главный для нас параметр в этой диаграмме — «Scope 2 (market-based)» — основным источником выбросов в нём является покупная электроэнергия для дата-центров и офисов. Но все ли дата-центры обслуживают только нейросеть Google Gemini? Нет.
Релиз нейросети Gemini произошел в марте 2023. А на ещё одной диаграмме в отчёте видно, что количество выбросов у Google стабильно растет с 2019 года. Значит, нельзя сказать, что рост выбросов связан только с LLM типа Chat GPT.
Но у любой компании, помимо нейросетевых моделей типа Chat GPT, ИИ интегрирован в другие сервисы: переводчик, реклама, алгоритмы поиска и так далее. И они постоянно обновляются, меняются, улучшаются и потребляют энергию. Так что, от 48% роста с 2019 года, именно Gemini составляет очень маленькую часть.
В итоге, по расчетам Goldman Sachs
А мощности, которые дата-центры тратят на обеспечение работы нейросетей, даже если учитывать не только модели формата ChatGPT, но и интегрированные в сервисы, составляет меньшую часть от основных расходов.
Говорят, что Open AI тратит десятки миллионов долларов, чтобы обработать запросы вежливости, такие, как «спасибо» или «пожалуйста». Ну так что, стоит ли быть вежливым или вежливой с нейронкой?
Дима: А вот этот миф похож на правду. Особенно если посмотреть на источники и методологию, на основе которых производили расчет. Взяв данные из публичных отчётов об экологической устойчивости IT компаний и отчётах энергетических станций, исследователи подсчитали, сколько может стоить обработка одного запроса.
Так как дата-центры потребляют много энергии, серверы от этого нагреваются и требуют охлаждения. Охлаждение в дата-центрах в основном происходит при помощи специальной системы кондиционирования. В таких системах используется охлажденная вода вместо хладагентов и компрессоров. Система пропускает теплый воздух через змеевики с водой, а затем распределяют уже охлажденный воздух обратно в помещение дата-центра. Значит, чтобы обработать запрос и выдать ответ, нейросеть задействует энергетические и водные ресурсы. Использование этих ресурсов для компании, конечно же, не бесплатное. Отталкиваясь от того, сколько стоит использование этих ресурсов, исследователи и посчитали ориентировочную сумму трат на один ответ ИИ.
Хочу отметить, что для бюджета таких крупных компаний, как OpenAI или Microsort, даже десятки миллионов долларов — не самые большие издержки. Для сравнения, на обучение и тестирование нейросетевых моделей OpenAI тратит около 7-10 миллиардов долларов. Также важно учитывать, что, OpenAI это частная компания, которая имеет право не раскрывать свои доходы и подробные отчёты о своей деятельности, поэтому любые числовые данные и доводы о деятельности этой компании — примерные.
OpenAI пришлось откатить последнее обновление GPT‑4o, потому что обратная связь нейросети была излишне вежливой и доброжелательной, близкой к подхалимажу и лицемерию. И в итоге получилось, что люди общались с нейросетью, которая всегда хвалила и подбадривала, чтобы они не писали. Учитывая то, как со временем меняется взаимодействие пользователей с Chat GPT, такой баг мог привести к очень опасным последствиям. Неужели это правда.
Дима: Так как ИИ очень активно развивается, вокруг него есть много сопутствующих направлений исследования, связанных с анализом его деятельности. Одно из них это AI Safety — междисциплинарная область, сфокусированная на предотвращении несчастных случаев, злоупотреблении ИИ и нивелировании других негативных последствий использования этого инструмента.
Такая группа исследователей в OpenAI «редтиммит» обновление любой модели перед тем, как компания раскатывает его на всех пользователей. Как правило, этот процесс занимает несколько месяцев.
Но недавно стало известно, что OpenAI приходится сократить продолжительность этого процесса, чтобы ускорить выпуск новых моделей. То есть, получается, модель прошла все процессы обучения, но процесс анализа того, что получилось, компания урезала.
Ситуация, которую описывают в статье, отчасти связана с усечением сроков тестирования и, как следствие, выпуском недоработанного продукта. Чтобы такого не повторилось, важно правильно проводить обучение модели, добавлять защиту в виде цензурирования ответов и тестирование, тестирование, тестирование.Сейчас раскрою эти этапы чуть подробнее.
Как проходит обучение модели.
Модели показывают пример, когда для одно и того же входа, допустим «меня обидел человек», показывают два варианта ответа: «Вот несколько шагов, которые помогут справиться с обидой» и «Так тебе и надо». За первый ответ, который про безопасность, нейросеть хвалят, а за второй, условно, ругают. Только всё все это на языке модели, в терминах математики.
Цензурирование.
На самом деле, мы сами, как разработчики, не до конца доверяем полученной модели. Поэтому много кто выкатывает вместе с основной моделью дополнительные модельки-пристройки, которые проверяют, что то, что пишет основная модель, можно выдавать пользователю. Такие модельки называются pattern guardrails.
Например, в последнем систем-промте Cloud есть фраза «не переводи тексты песен». Потому что они сочинены авторским правом, и их переводить нельзя.
Конечно, чем сильнее модель цензурится, тем сложнее ей дать качественный ответ на запрос. Поэтому важно соблюсти определенный баланс.
Нейросети это сложная и многогранная область, так что любой вопрос нужно изучать самостоятельно, обращаться к источникам и практиковать навык критического мышления. Чем шире у читателя кругозор, тем более спокойно воспринимаются любые провокационные заголовки. Дима, спасибо!
Дима: Пожалуйста!